Learning in the Dark: Lessons Learned in Unsupervised Learning
CyberPoint has seen great success in using supervised machine learning for malware detection. A while back, however, some colleagues and I set out to investigate whether we could make any interesting discoveries by applying unsupervised learning to CyberPoint's malware dataset.
First, for the uninitiated, a little on the difference between supervised and unsupervised learning:
In supervised learning, one has a set of samples, each with an assigned label. In the field of malware analysis, a sample would typically be a file, and its label might be either benign or the malware family to which it belongs. The goal is: given a new sample, correctly predict its label. Supervised learning is a powerful tool that allows one to easily extract and utilize the knowledge contained in a dataset (e.g. of malware) that's already been analyzed, and automatically apply it to a new sample. One application of this is for fast detection of malware, even when designed to evade signature-based detection — while it is relatively easy to make small changes to a binary so that it doesn't match an existing signature, it is harder to change its essence as learned by a complex classifier.
Unsupervised learning, on the other hand, works without labels, and endeavors to understand the "structure" of a dataset. Most typically, it entails clustering, i.e., partitioning the data into "clusters" such that items in the same cluster are "similar" and items in different clusters are "different." If that sounds vague, it's because it is. While clustering algorithms are often taught as if they're a simple cut-and-dry problem-solving technique, using them in real life is a different story, as we will soon see.
I was actually wary of unsupervised learning even before we began. I was familiar with Kleinberg's negative result1 on clustering, which says that no clustering algorithm can be simultaneously rich, scale-invariant, and consistent2. I had also seen more recent work3 which poked holes in standard practices for determining the optimal number of clusters and measuring cluster goodness.
Nonetheless, we love playing with data (especially malware), so we dove in. We applied a variety of clustering algorithms, as well as other techniques, such as self-organizing maps and dimension reduction. We looked at high-level features and low-level features, as well as feature-less distance functions4.
Not surprisingly, we ended up with a big pile of clusterings of our data. Woohoo, right? But, wait. Were they informative? Were they "good"?
In our analysis, a few interesting things came to light, most of which were, at best, tangential to the task at hand:
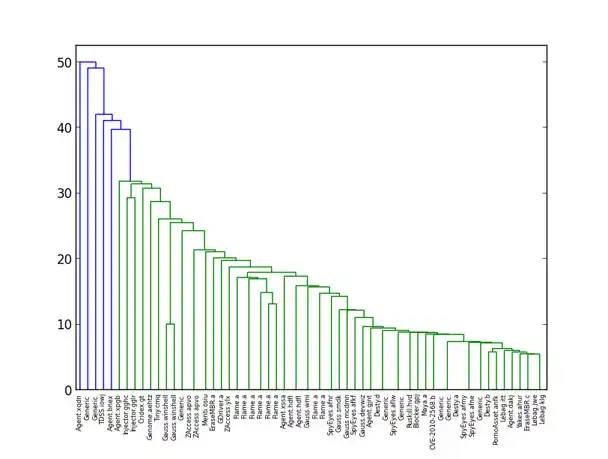
- Some of our analysis indicated that Gauss and Flame were probably related… but it was already old news that both were nation-state cyber-surveillance malware, with Gauss based on the Flame platform.
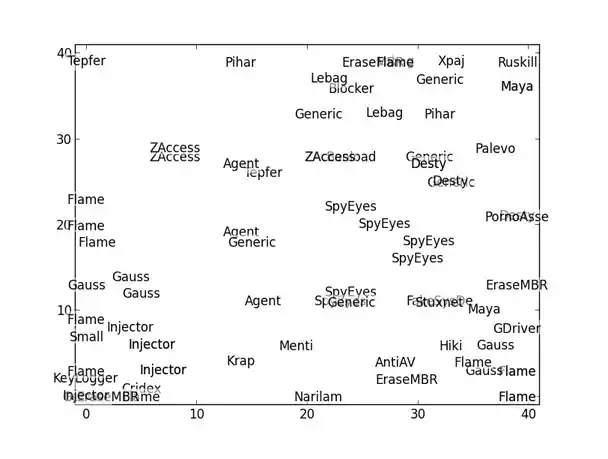
Figure 1: Self-organizing map reflects relationship between Gauss and Flame malware - K-nearest neighbors is a useful supervised learning technique that feels unsupervised. With the right distance function, we found it performed almost as well as the state-of-the-art classifiers that had come out of our supervised learning efforts, while being much simpler to understand. When one has a representative set of known malware, looking at the distance to its nearest neighbor is a very simple way to determine whether a new sample is likely to be a new strain of malware.
- Normalized Compression Distance, a popular distance function used in a wide variety of applications, doesn't behave at all as expected on large files, but can be improved with some simple modifications. (For more details, see my recent paper5 in the Journal of Computer Virology and Hacking Techniques… or wait for my next blog post.)
- We did gain some insight into the features we were using, which allowed us to make improvements to our supervised models in DarkPoint. (This, however, was really due to playing around with the features and not the fact that we were specifically doing unsupervised learning.)
But, mostly, though, what we had to show for our efforts was a big pile of clusterings that didn't provide any definitive insight.
In the midst of this, I happened to discover a presentation by Rich Caruana, entitled "Clustering: Probably Approximately Useless?"6. While validating my sentiments that clustering was something of a can of worms, he also had some interesting suggestions for making it less so. One, meta-clustering, entails clustering your clusterings, and creating a representative cluster from each cluster of clusters, so that those sorting through them could more quickly hone in on which ones were of interest. This sounded very promising, but, in practice, didn't yield any additional insight for us. The second, semi-supervised clustering, entails having subject matter experts specify, before clustering, that certain samples belong in the same cluster and certain samples belong in different clusters; then they're guaranteed that any clustering created will pass a sanity check for whatever kind of structure they're seeking. This wasn't readily applicable in our situation, as we didn't know what sort of structure we were seeking. Still, both ideas gave me renewed hope for the general applicability of clustering.
Lessons Learned
- Results May Vary: While different supervised learning techniques often differ only slightly in their accuracy, different unsupervised methods can (and often do) yield vastly different results.
- Imagine clustering fruits. One clustering might organize them by shape, another by color, another by size, and others by some combination of the above.
- Success is Undefined: While supervised learning provides quantifiable results, the success of unsupervised learning is really in the eye of the beholder.
- Which of the fruit clusterings is good/useful/informative? If your goal is to decide which new fruits you should try if you like apples, bananas, and grapes, but not pears, probably none of the above.
- Clustering is Harder than it Looks: In textbook examples, clustering often yields idealized clusters, where members of the same cluster are very similar, while members of different clusters are totally different. In reality, your data may not split neatly into tight clusters; it may be more of a continuum.
- This was our experience with malware. However, it's possible that we just didn't stumble onto the right algorithm or distance or feature set to yield those magical clusters.
- Supervised Learning Gives You More Bang for your Buck: If you already have labels for your data that capture what you care about, you should probably be using supervised learning, rather than hoping to stumble onto the right clustering in the dark.
- Compromise is the Spice of Life: If you have limited labels (not enough for supervised learning), semi-supervised clustering is worth checking out.
That said, if you have a dataset that you don't know much about, and you're not sure where to begin, unsupervised learning might fit the bill. But if you find yourself drowning in disparate clusterings, none of which seems to be quite what you'd hoped for, know that you're in good company.